Hi, welcome to my portfolio.
My name is Oje Williams and simply put, I am passionate about data and how we can learn from it. I have a bachelor’s in Applied Mathematics which developed my love for statistics and I recently obtained a master’s in Statistics with a concentration in Data Science. I am an aspiring Data Scientist who would love to marry my skills, knowledge and desire to learn, with using data to provide business insights as well as data driven solutions.
Skills and technologies I have aquired along the way are:
- Programming: Python, R, SQL, PostgreSQL
- Data Science Packages: Pandas, NumPy, Matplotlib, Seaborn, Scikit-Learn, NLTK, SpaCy, TensorFlow, etc.
- Data Science/Mining Algorithms: Regression( Linear, Multi-Var, Ridge, Lasso Elastic-Net), Classification( KNN, Random Forest, Hierarchical Clustering etc.), Linear Discriminant Analysis, Principal Component Analysis, Natural Language Processing
- Big Data Technologies: AWS (EC2, Elastic Search, Kibana, Kinesis, Athena, S3), Docker, Hadoop, Spark
- Data Visualization Tools: Tableau
- Currently Learning: Git, A/B Testing
Connect with me on LinkedIn.
View my Github Profile here.
Email me here: ojewilliams17@gmail.com
Projects:
Customer Segmentation Of Mall Data
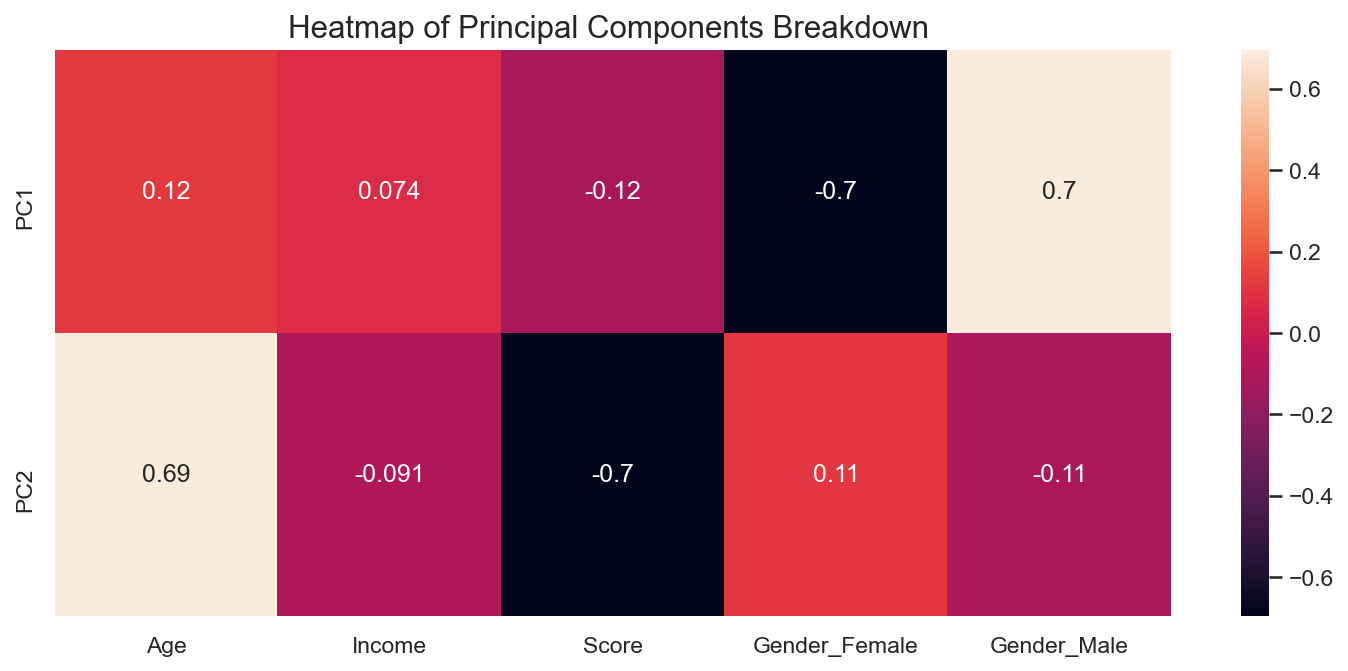
Customer Segmentation is the practice of dividing the customers of a company into different groups that possess similarities in each group. The objective of segmenting the customers is to ascertain how to relate to customers in each segment so that we can maximize the value of each customer to the business. Ideally this allows us to tailor our appraoch to each customer group based on their interests, demographic profile or even preferered method of communication and interaction. This project investigates Mall data obtained from Kaggle and it was used to create six customer groups based on K-Means, Hierarchical Clustering and Principal Component Analysis.
K-Means Clustering
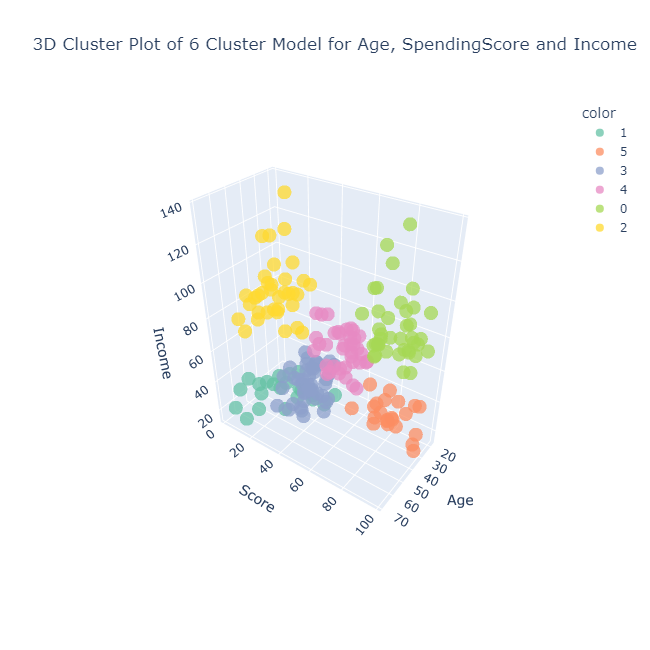
Hierarchical Clustering
Principal Component Analysis
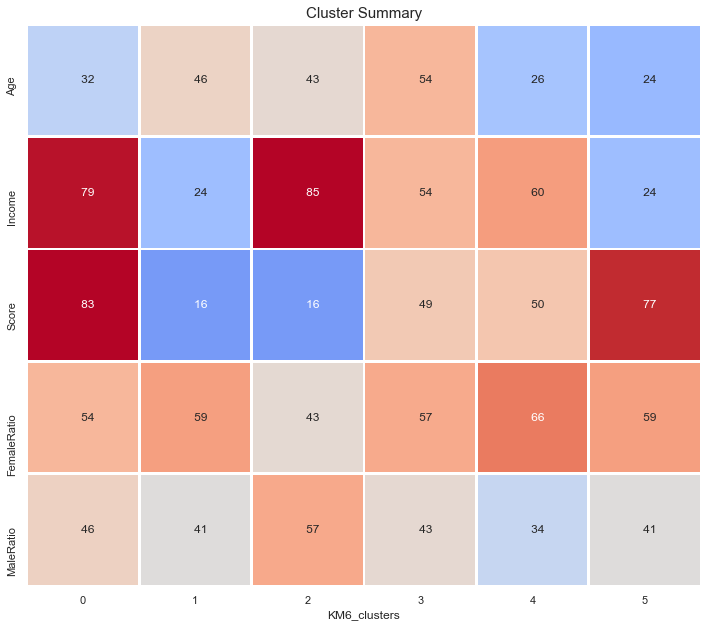
Cluster Summary
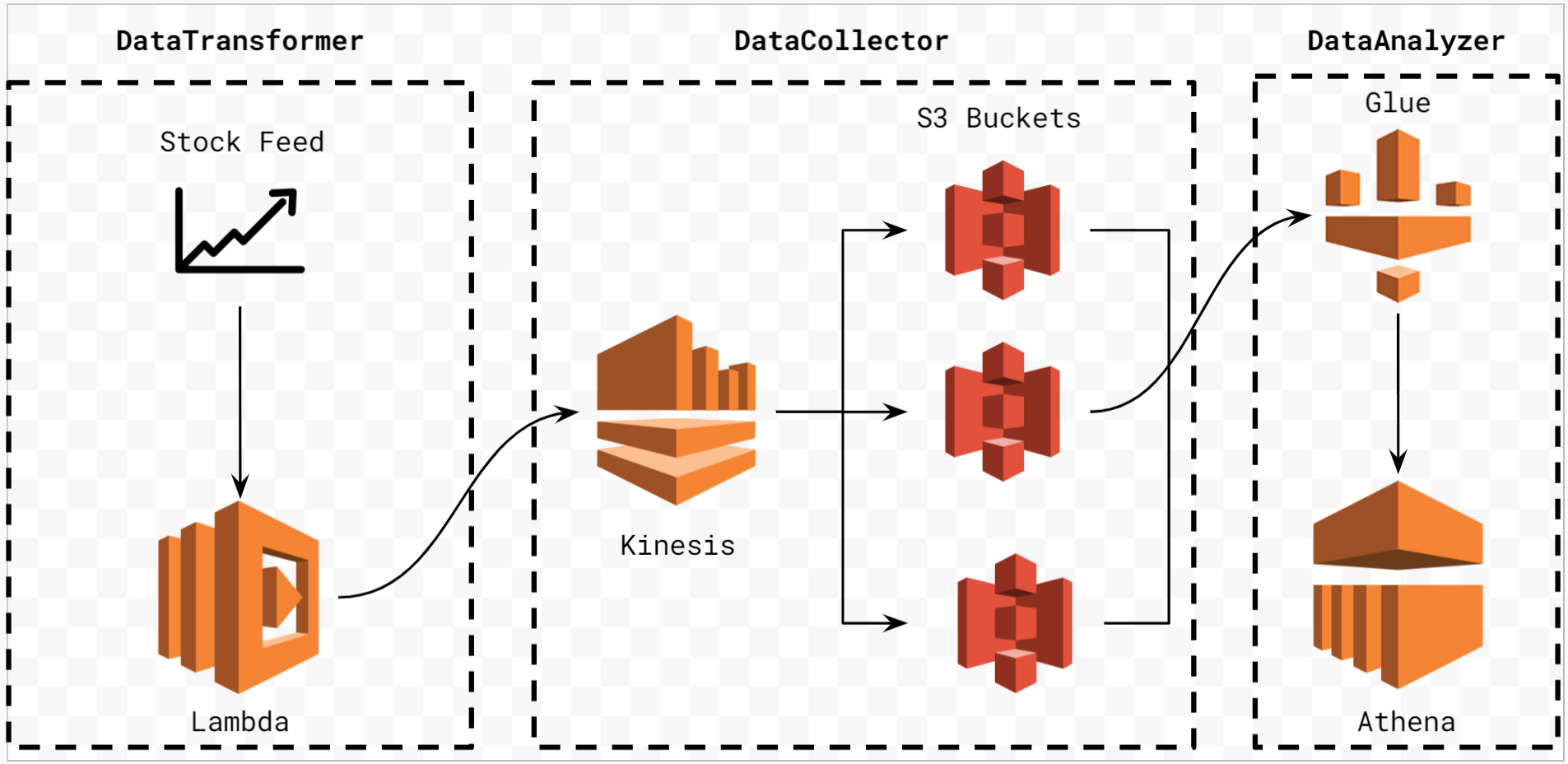
Streaming Yahoo Finance Data with AWS Lambda
This project involves setting up a few AWS technologies to generate near real time finance data records for interactive querying. This will allow us to capture and analyze data that is being constantly generated in or near to real time. We will utilize the yfinance module that provides a suitable and effective way to download and view historical market data from Yahoo! finance. We will be taking a look at the following stocks:
- Facebook (FB), Shopify (SHOP), Beyond Meat (BYND), Netflix (NFLX), Pinterest (PINS)
- Square (SQ), The Trade Desk (TTD), Okta (OKTA), Snap (SNAP), Datadog (DDOG)
The aim is to leverage an AWS Lamda function as well as AWS Kinesis, S3, Glue and Athena to capture data over a specific time period and run a few queries as well as provide some analsyis and visualizations.
Workflow
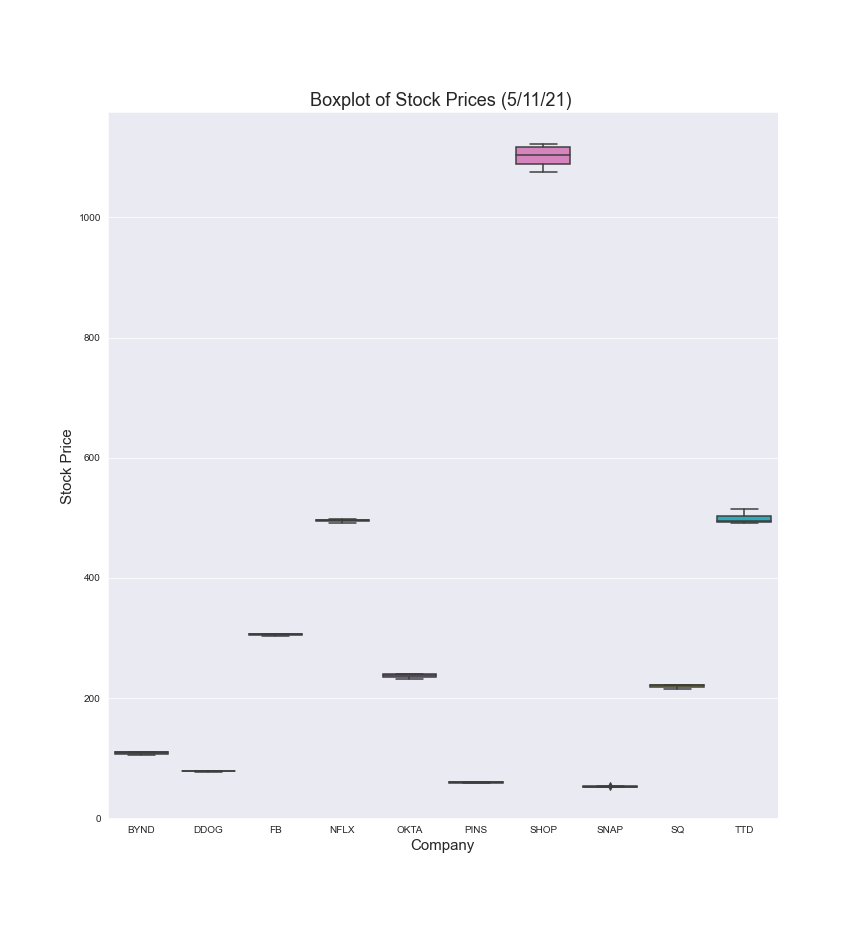
Boxplot of Company Stock Values
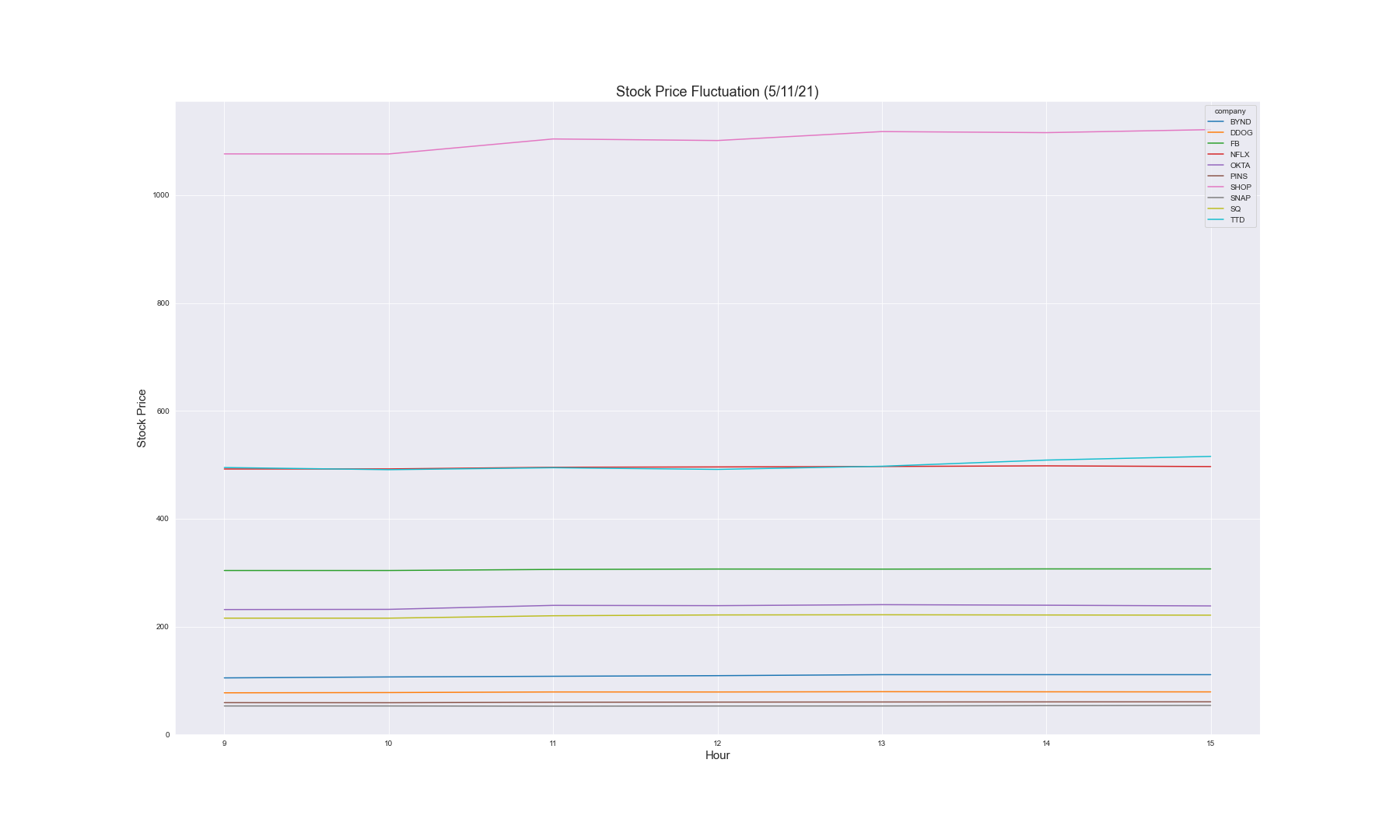
Price Movement Over a Day
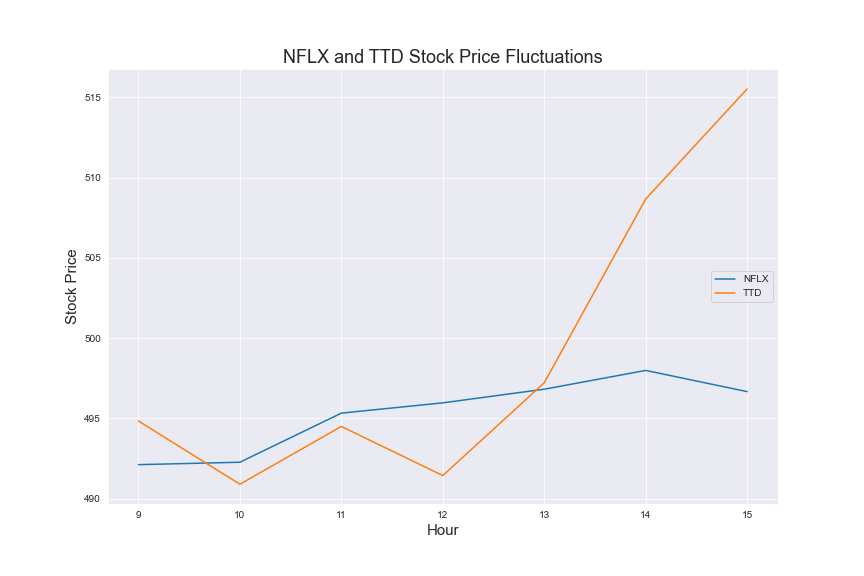
Comaprison of Netflix and The Trade Desk
Regression-Model-Comparison
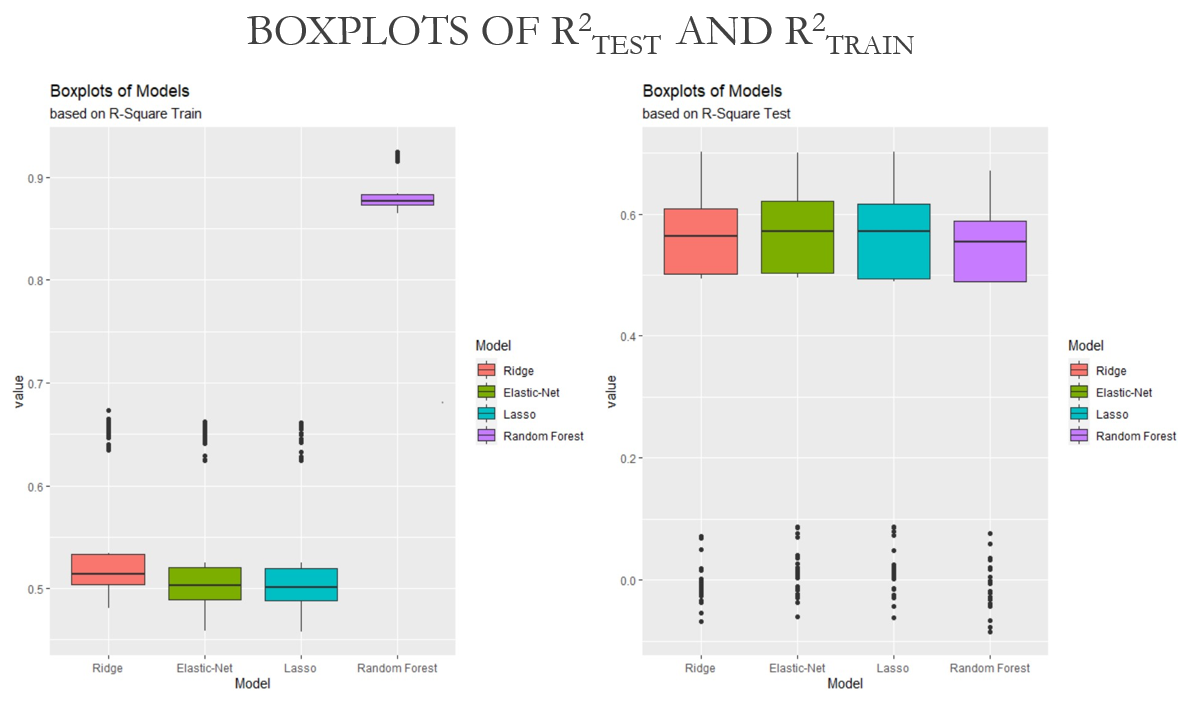
This project was conducted as part of a Data mining Class (STA-9890). It involves an investigation into survey data utilizing Lasso, Ridge, Elastic Net and Random Forest. Essentially this project seeks to ascertain which of the named models performs best on our data set when trying to predict the height of Slovakian students.
Lasso Regression: Lasso stands for Least Absolute Shrinkage and Selection Operator is a regression technique that allows for an easy way in selecting important features from our dataset because it supresses the coefficient of many features to zero. It heavily penalizes the absolute size of coefficients and based on your tuning parameter; you can control how many of your coefficients you want to be pushed to zero.
Ridge Regression: Ridge penalizes the squared size of coefficents and as such it leads to overall smaller coefficients as it pushes them closer to zero. Essentially, Ridge allows us to shrink the the coefficeints of features which sometimes allows us an easier time to see which features are most important.
Elastic-Net Regression: Elastic-Net is a combination between Lasso and Ridge. It blends penalizing based on absolute size and squared size of coefficients.
Random Forest: Random forest is a decision tree classification technique. Essentially it posseses many individual trees that can easily produce their own class prediction, which is then used to determine the overall prediction of the model.
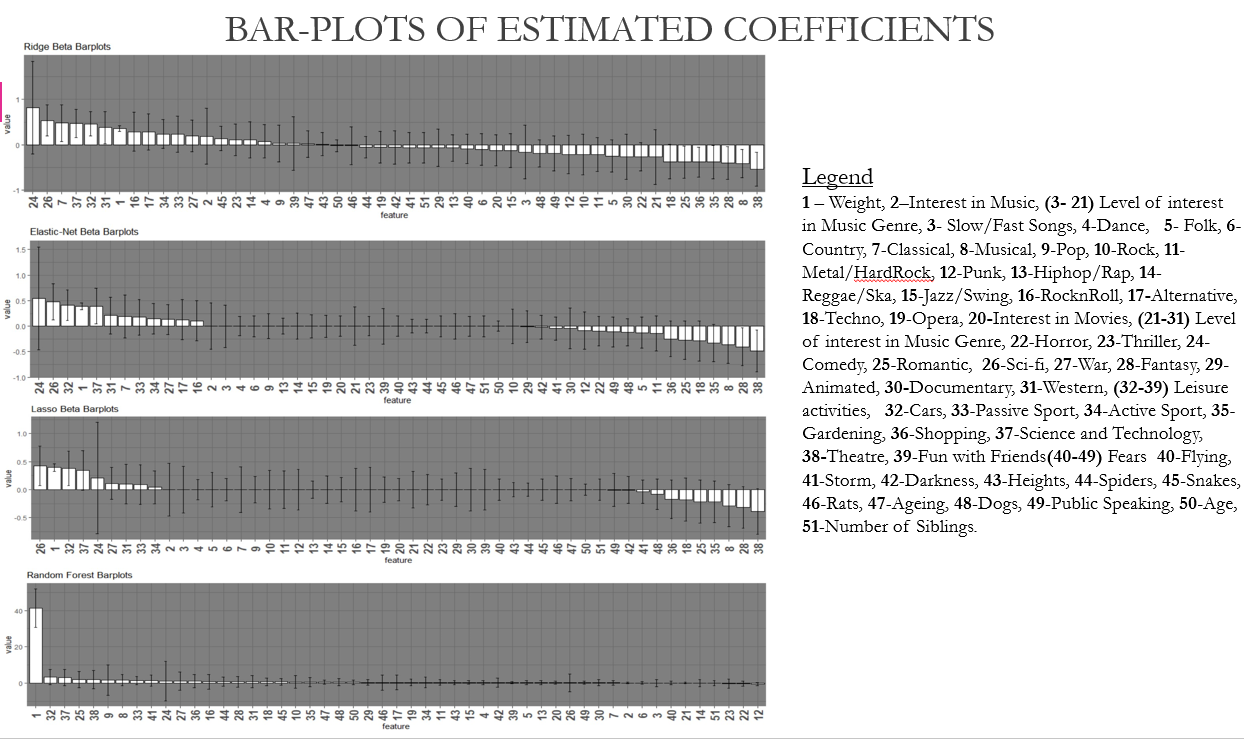
Top Music predictors: Classical, Musicals, Rock, Metal, Alternative.
Top Movie predictors: Comedy, Sci-Fi, Horror, Fantasy, War.
Other Top Predictors: Weight, Interest in Cars, Passive Sports, Shopping, Science and Technology
R-Squared Boxplot
Coefficient Boxplots
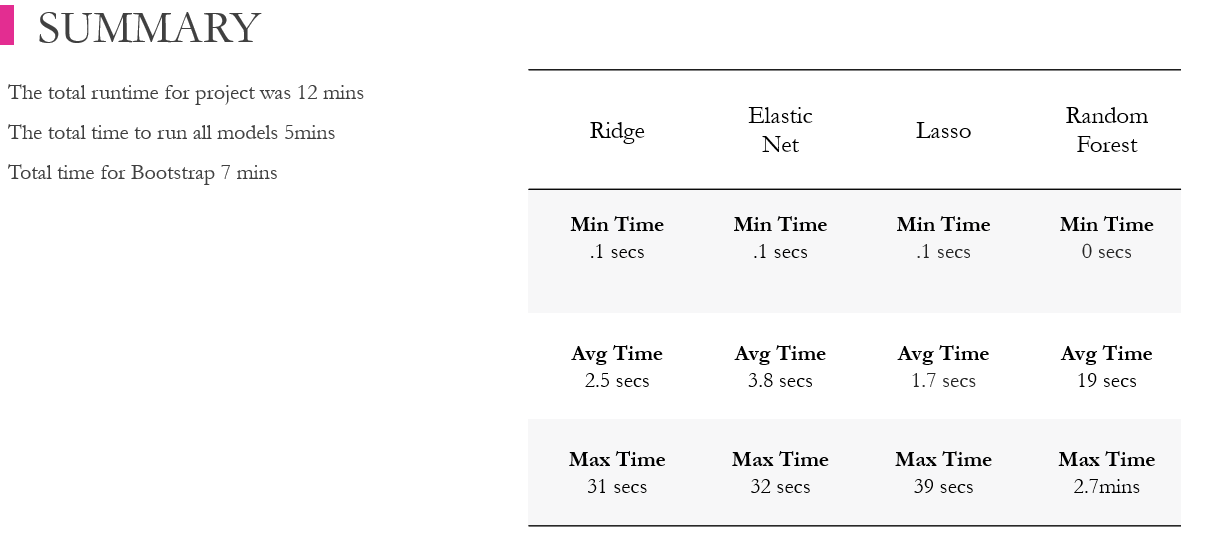
Summary
Game of Thrones Script Analysis
Game of Thrones (GOT), is a fantasy drama television series that contains 73 episodes in 8 seasons. We analyzed a complete set of the script from all the characters for all seasons through Natural Language Processing techniques such as sentiment analysis, aspect mining, tokenization, and Named Entity Recognition (NER). We tackled topics such as the change in main characters’ sentiment, frequent words used in each family, and the comparison of the word usage of the two main characters. This allowed us to provide better and deeper insights to the audience. The GOT script analysis can help the audience understand the impact of each main character such as Tyrion, classify the attitude of each family, and learn alot about any of the main characters in 10 mins or less.
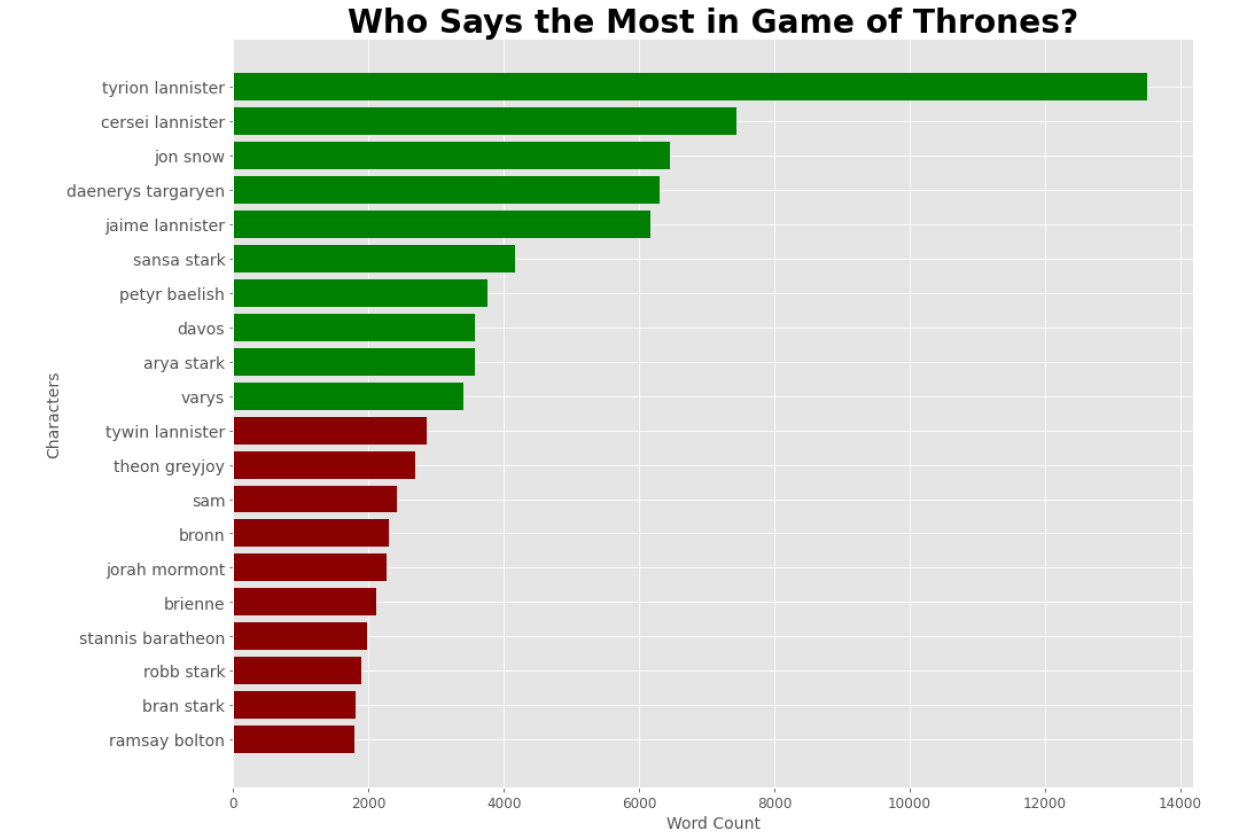
Most Talkative Characters
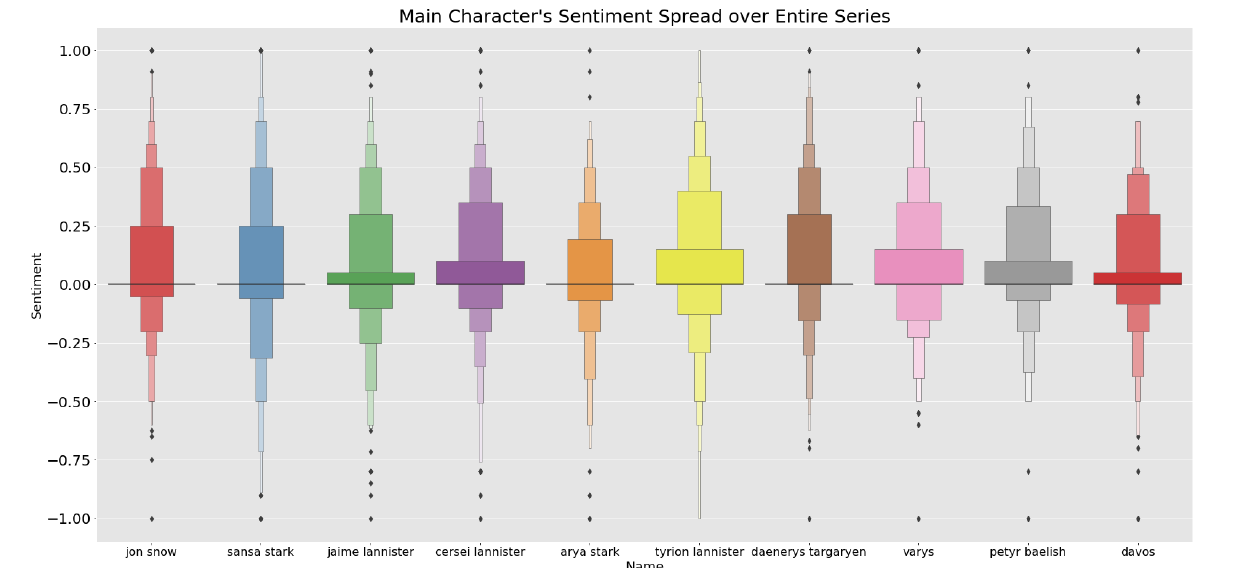
Sentiment Spread
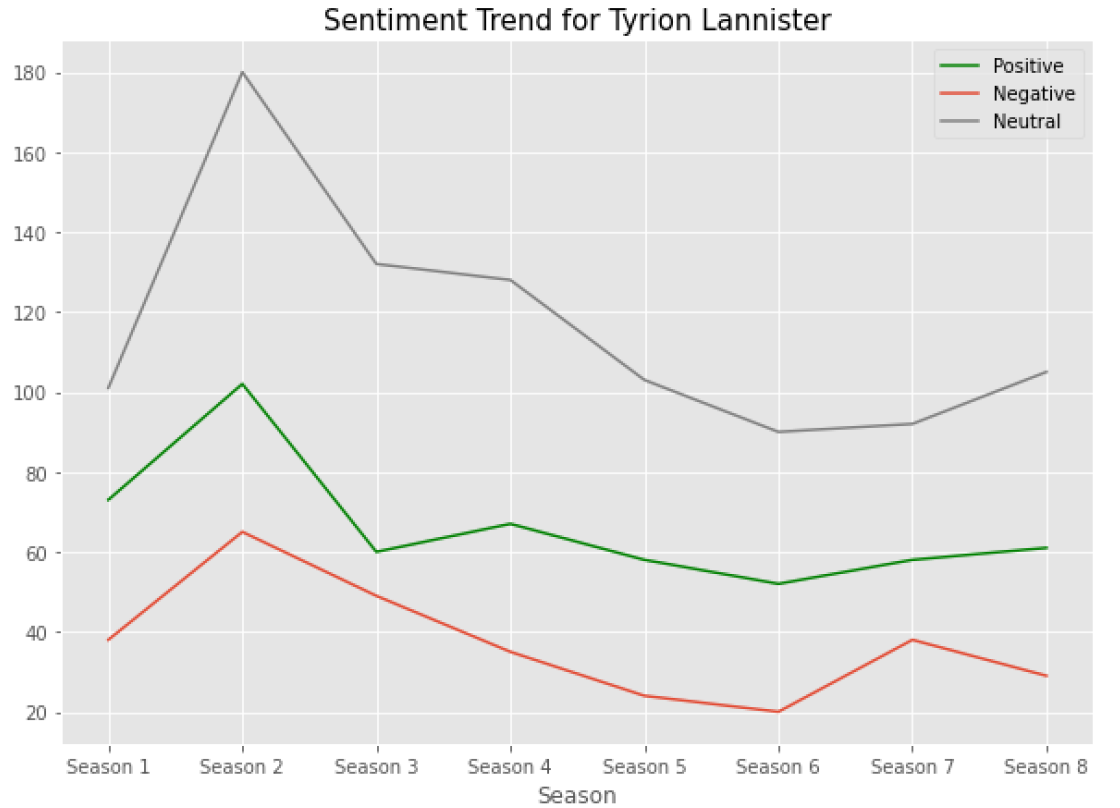
Tyrions Sentiment Over the Seasons
Multivariate Analysis of Louisianna and Mississippi Parishes
Multivariate Regression
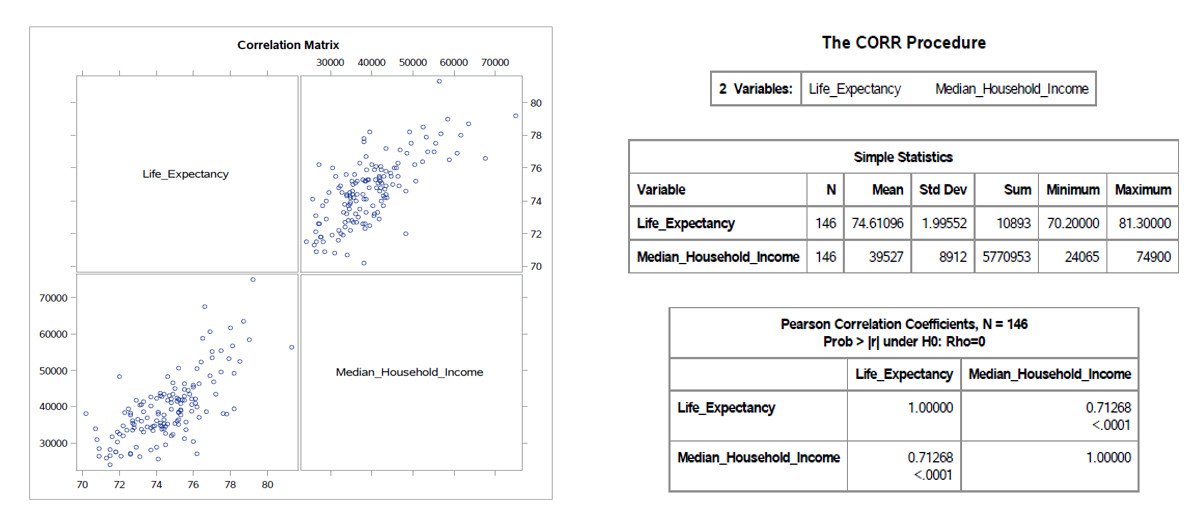
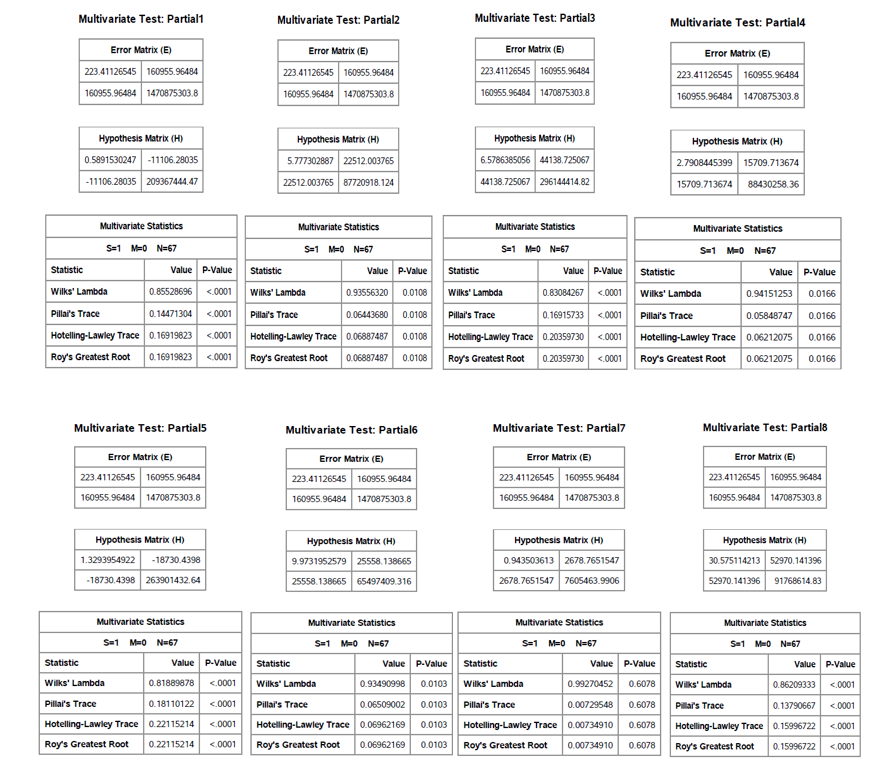
The purpose of this multivariate analysis was to study the relationship among varying features related to the States Mississippi and Louisiana. The focus was on Median Household Income (MHI) and Life Expectancy(LE). After checks for linearity by calculating and plotting the correlation, MHI and LE had a correlation hich was not only positive but also relative strong (r = 0.71). The test for overal regression indicated based on Wilk’s, Pillai, Lawley-Hotelling and Roy’s test indicated that there was the presence of strong linear associations between the responses and the predictors. After the test significance all of the predictors were significant except the predictor ‘Excessive Drinking Rate’(x7) and the two most important predictors when adjusted for the other predictors were ‘Population Under 18’ (x1) and ‘African American’ (x2).
Correlation
Test of Overall Regression
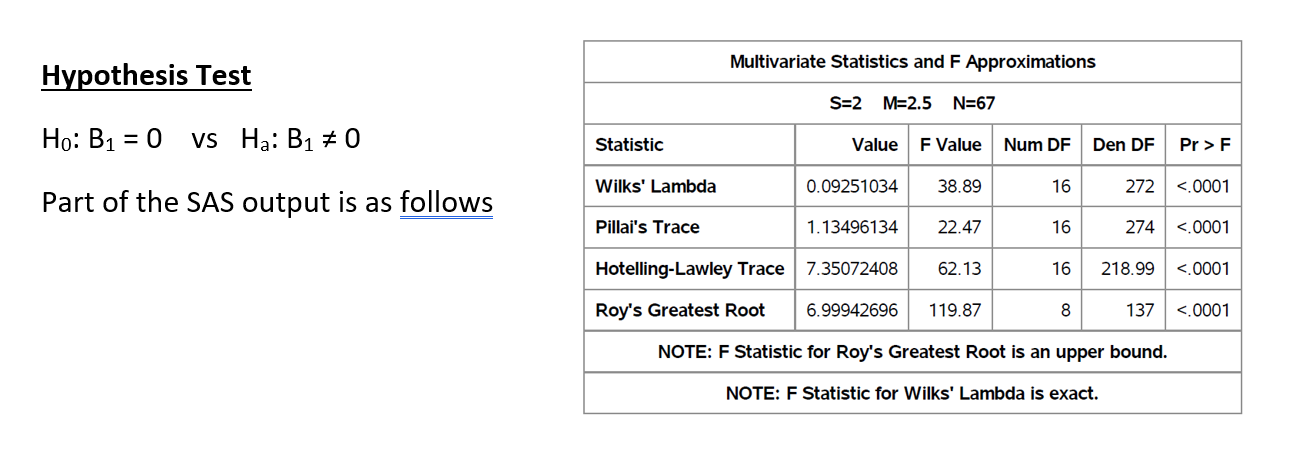
Tests of Significance
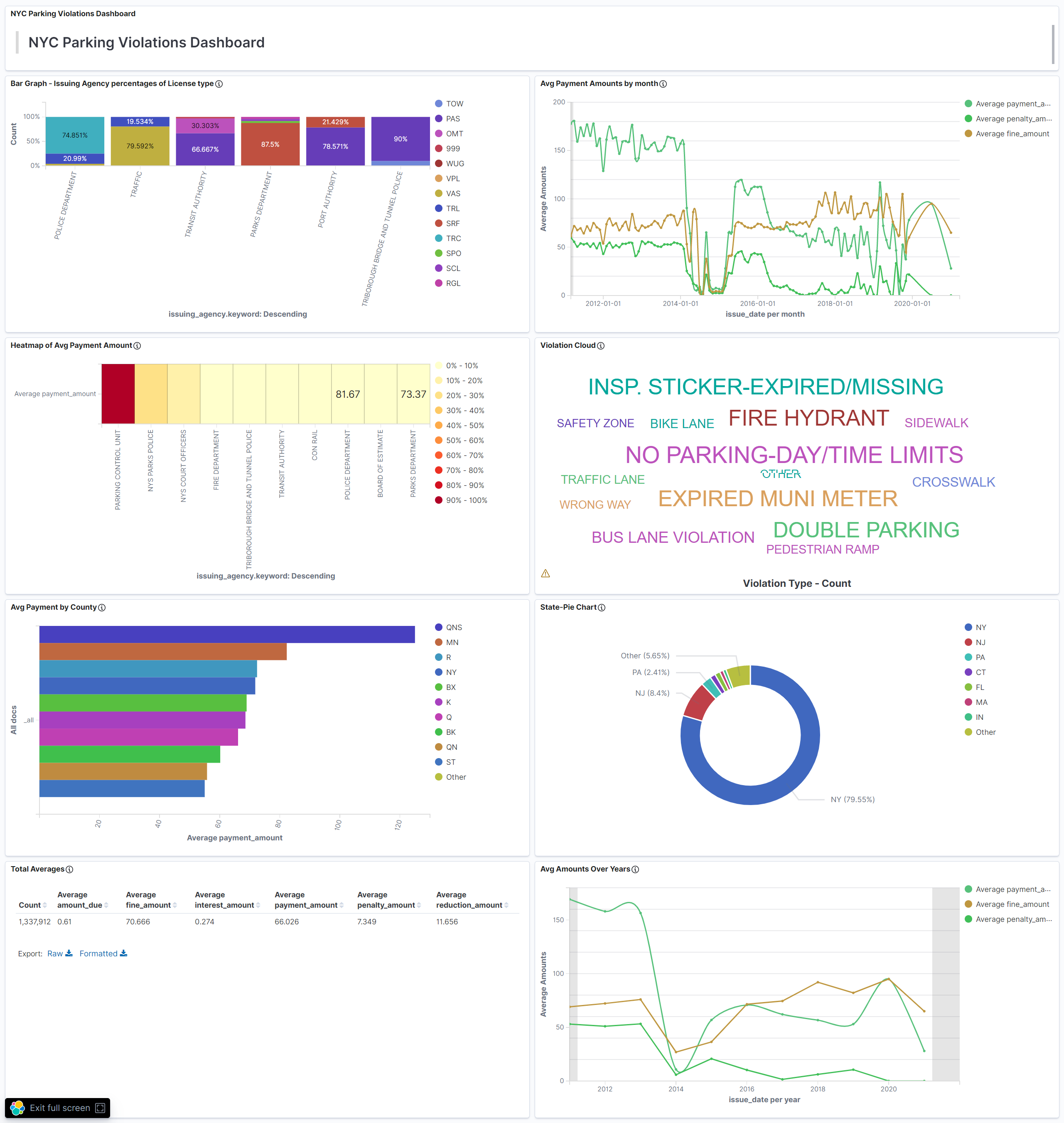
Analyzing-Millions-of-NYC-Parking-Violations
This project involves interacting and analyzing NYC parking violations over the last decade through the Socrata Open Data API. To achieve this I utilized a EC2 instance from Amazon Web Services, the Linux terminal, Docker, Elasticsearch and finally Kibana.
Parking tickets are a headache for most people but for some states it’s a tremendous money maker with them raking in millions if not billions in fees and fines. Luckily, we are afforded a chance to analyze this data through NYC Open Data which is a free public data site which offers an api for this very purpose. The Open Parking and Camera Violations api is a very large data source that can be much more easily and efficiently handled through cloud computing and thats what we plan to do here.
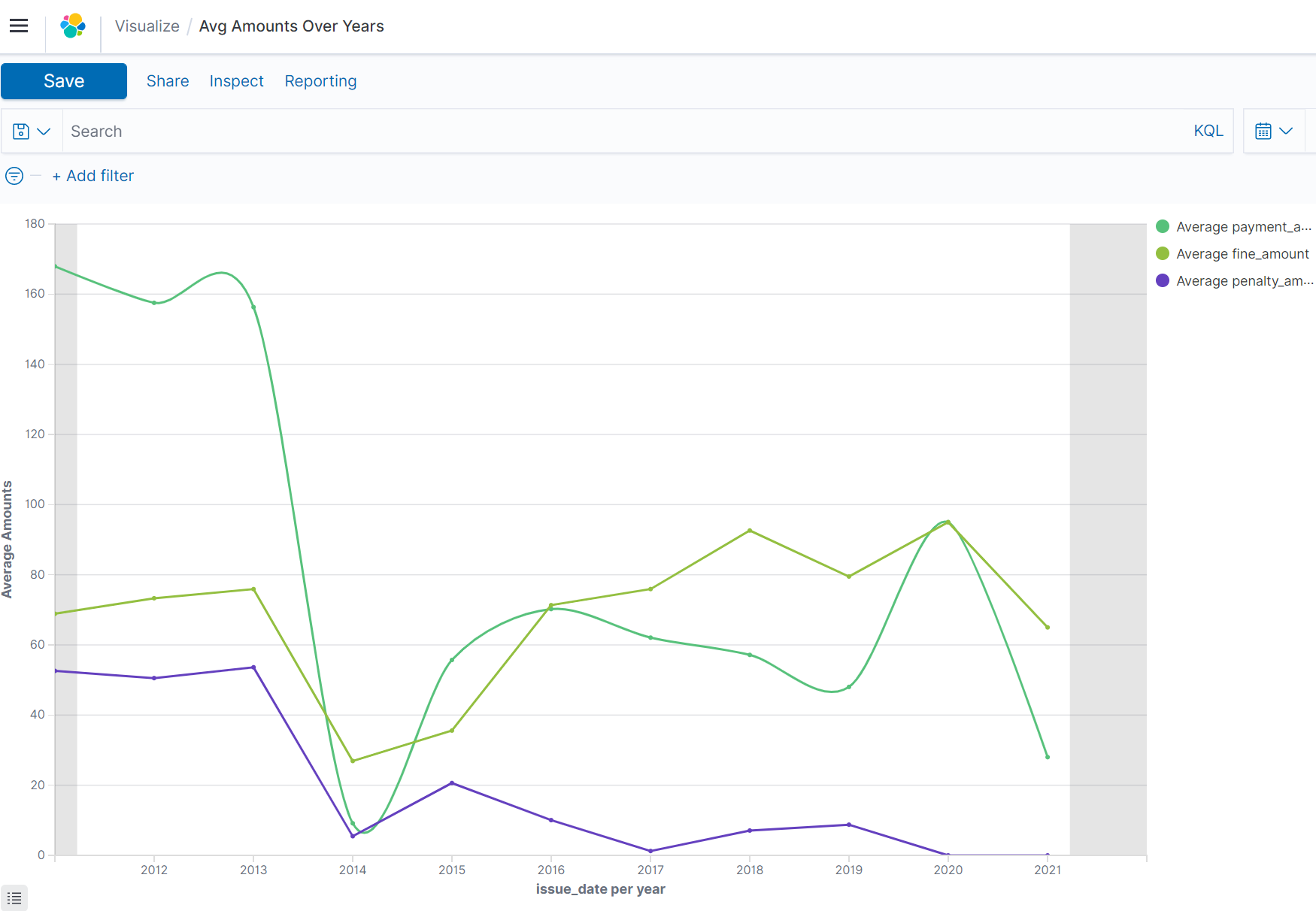
The Average Payment,Fine and Penalty amount over the last decade
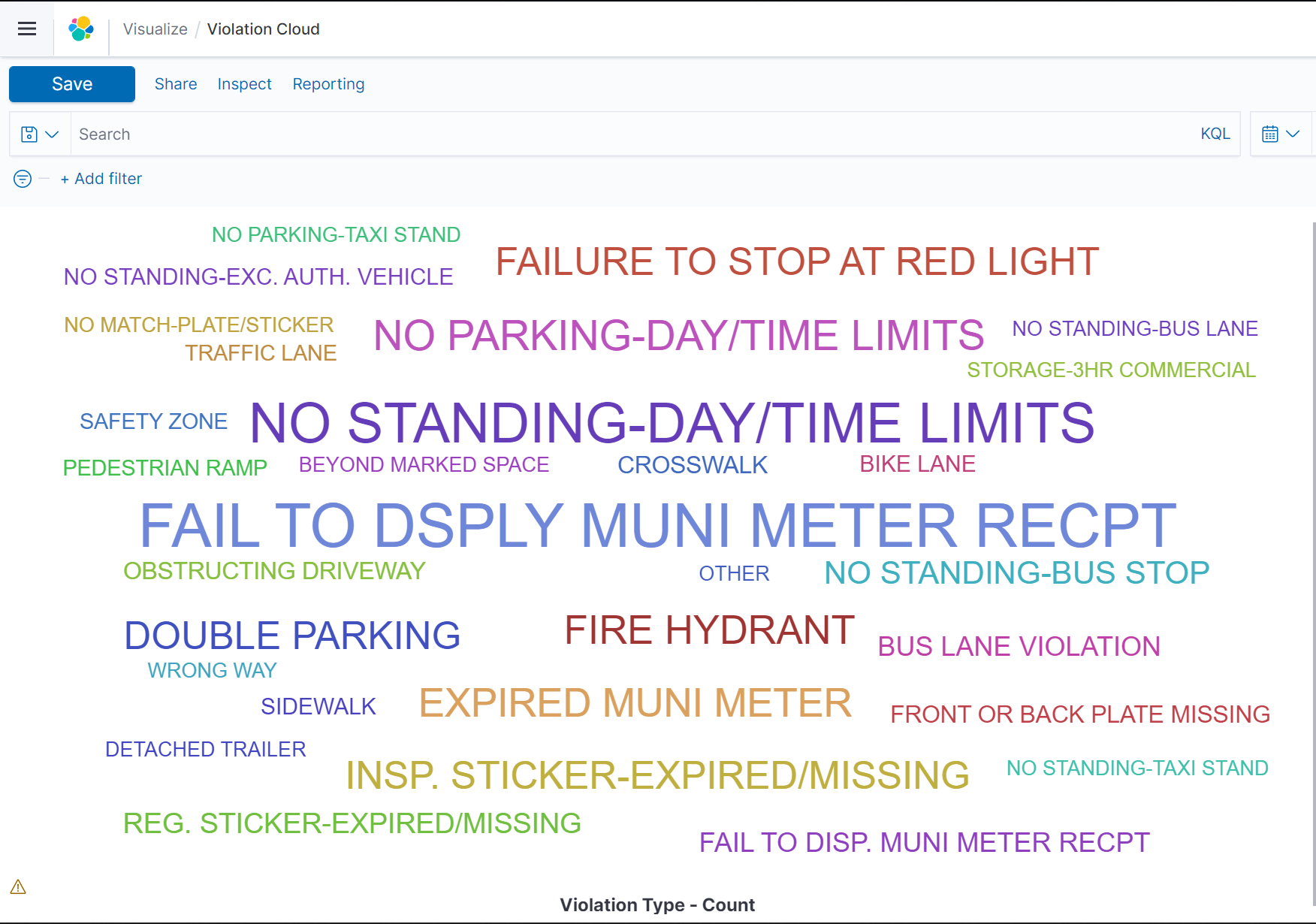
The Top 50 Parking Violations Wordcloud
Total Dashboard
Analyzing Yelp Reviews Dataset
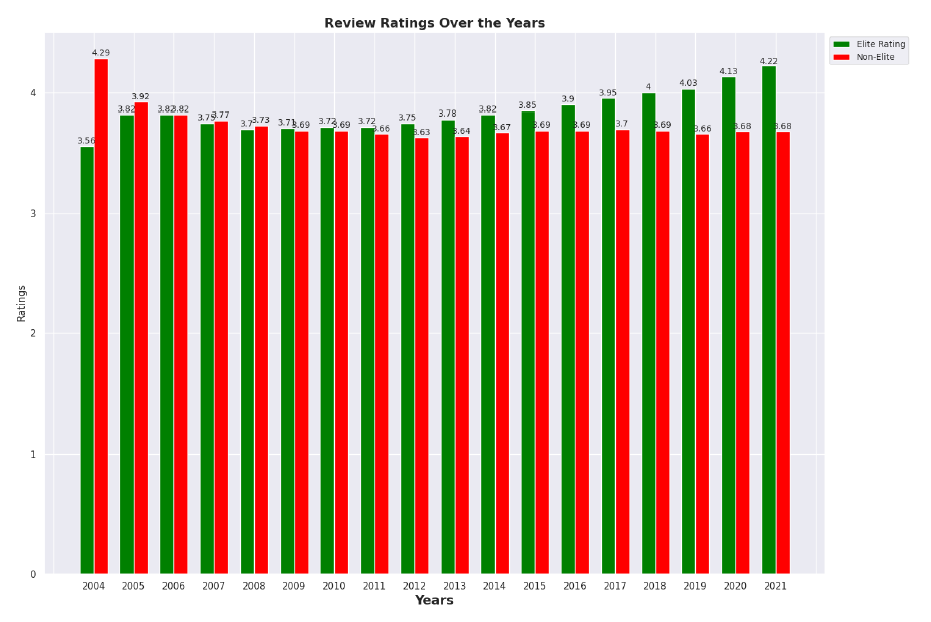
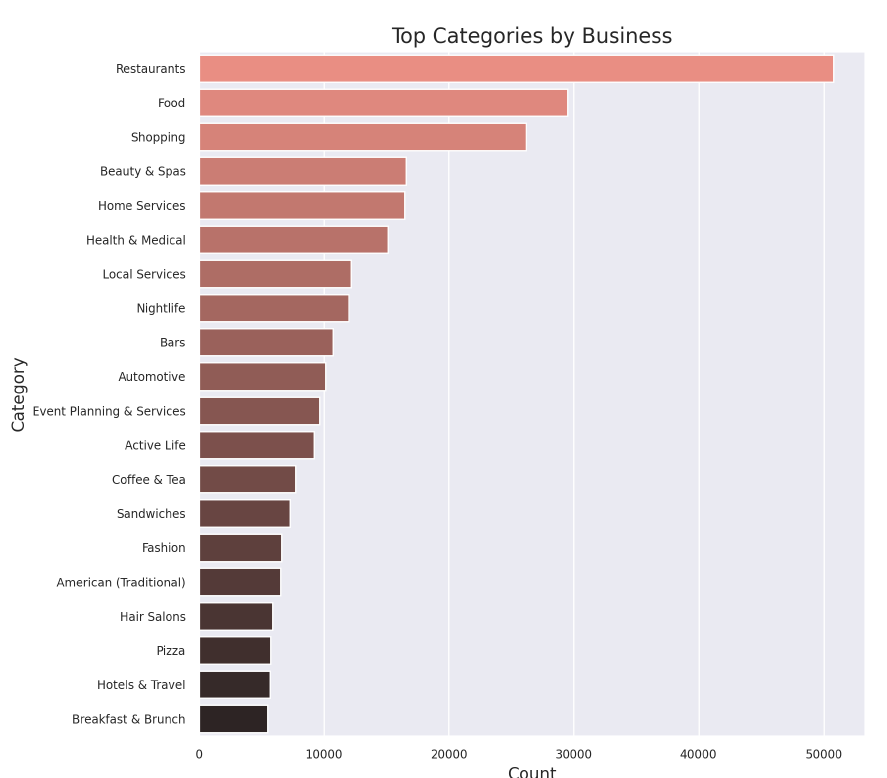
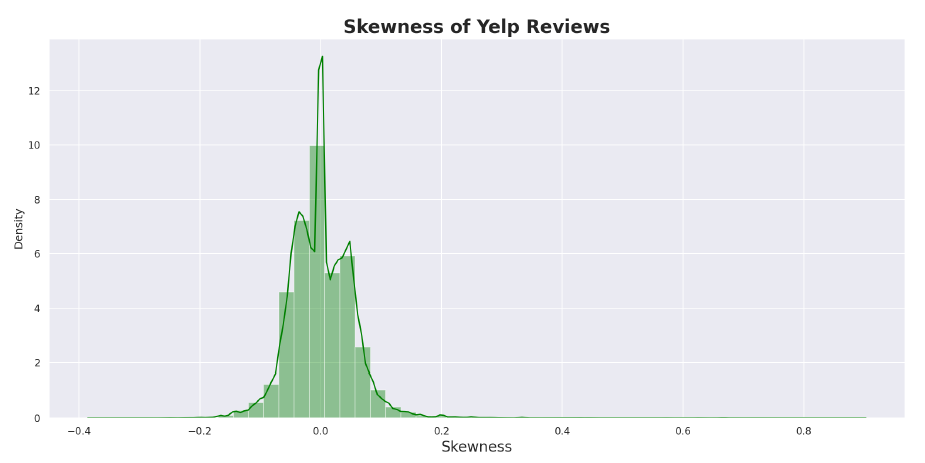
This project involves diving into a dataset of Yelp reviews and seeing what interesting things we can find. The dataset is a collection of Yelp’s reviews, user data and businesses across 8 metropolitan areas in the USA and Canada. The Yelp Dataset is a great resource for us to Extract, Load and Transform as a Big Data project. The dataset is quite large (11gb) and therefore to investigate it we will leverage a Spark Cluster on AWS EMR for loading the data as well as an S3 bucket for uploading the data while all analysis was completed using Pyspark, SQL inside a Jupyter Notebook. As part of the analysis I investigated the skewness of the data as well as the trustworthyness of Elite reviews.
Top Business Categories
Yelp Review Skewness
Review Comparison